
Syksyllä 2022 tuhansia marjakuvia arkistoitiin suurten kuvametatietojen kanssa, viimeisteltiin koneoppimismalli ja pidettiin projektin loppuseminaari. Marjamasiina-projekti oli päättynyt ja se oli kiehtova matka käytännön koneoppimiseen.
Marjakone-hanketta rahoitti Interreg Nord, mukana olivat Luonnonvarakeskus (LUKE) ja Norjan biotalouden tutkimuslaitos (NIBIO), kehittäjänä toimi Frostbit Software Lab Lapin ammattikorkeakoulusta. Hankkeen tavoitteena oli tutkia, onko mahdollista koneoppimisen avulla tehdä nykyisestä marjasadon arvioinnin mittausprosessista vähemmän riippuvainen manuaalisesta työstä, jolloin kenttämittauksia voidaan tehdä huomattavasti enemmän ja avata uusia tapoja marjasadon arviointiin.
Nykyinen marjasadon arvioinnin mittaus tehdään laskemalla manuaalisesti jokainen yksittäinen marja eri materiaaleista luodun kehikon sisällä (Kilpeläinen 2016). Kehys muodostaa tarkalleen yhden m²:n alueen. Metsässä on viisi kehikkoa, jotka on asennettu maalajiltaan vaihteleviin paikkoihin (marjahavainnot.fi 2022). Kaiken tämän manuaalisen työn jälkeen aineisto ei ole vielä tarpeeksi kattava tarkempien tutkimusten tekemiseen, sillä prosessi on sekä kallis että työläs (Bohlin 2021).
Marjamasiina-hankkeessa tutkittiin tapaa, miten syväoppimista voitaisiin käyttää apuna marjojen laskennassa ja siten tehdä prosessista huomattavasti kevyempi. Suunnitelmana oli käyttää syväoppimista hyödyntävää tietokonenäköä marjojen havaitsemiseen ja luoda toimiva mobiilisovellusprototyyppi, taustajärjestelmineen. Alkuperäiseksi kohdelajiksi haluttiin vain mustikka (Vaccinium Myrtillus), mutta mukaan otettiin myös puolukka (Vaccinium Vitis-idea), jotta saataisiin kattavampi kuva siitä, miten tekniikka toimisi eri lajeissa. Molemmat marjat laskettiin kasvuvaiheissa ”kukka”, ”raaka” ja ”kypsä”.
Syväoppimisen tekniikat
Tärkeimmät vaiheet Marjamasiina-hankkeen tehtävän täyttämiseksi olivat tietokoneen syväoppimisen mallin kouluttaminen marjojen tunnistamiseksi kuvista ja tämän tietokonenäön avulla laskea marjat kuvista sekä verrata havaittua marjojen lukumäärää kenttämittauksella laskettuun marjojen määrään.
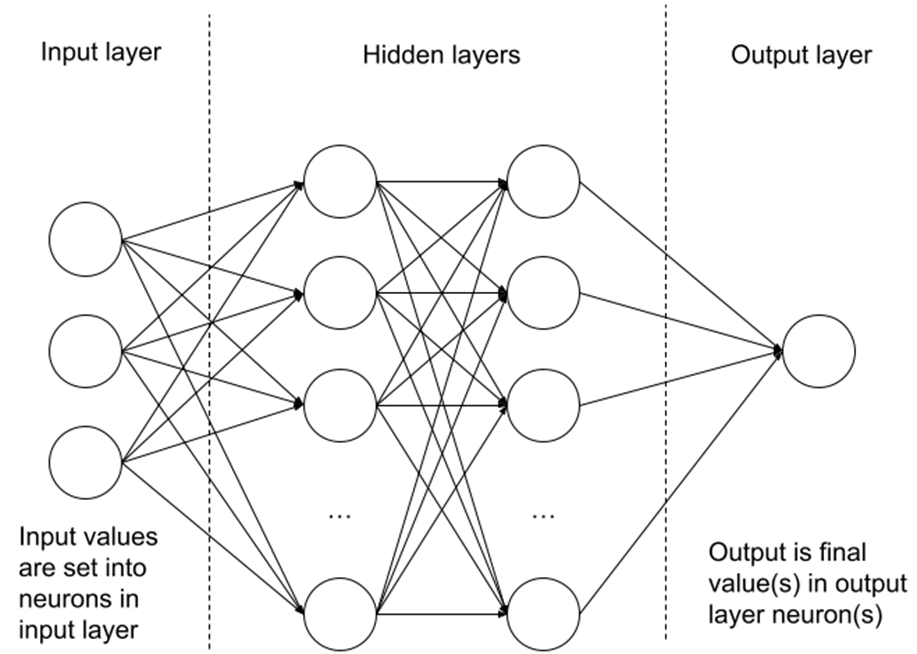
Perinteinen keinotekoinen neuroverkko (Artificial Neural Network, ANN) muodostuu tuloneuroneista, piilokerroksista ja lähtökerroksesta (Kuva 1). Kuvien luokittelussa sisääntulokerroksen arvoiksi lisätään kuvan pikselien arvot (Gogul 2017). Weight- ja bias -arvot neuroneissa ja yhteyksissä johdetaan koulutusprosessissa. Weight ja bias -arvoja käytetään tulosarvojen laskemiseen sisääntuloarvoista, kun kaikki alkuperäiset pikseliarvot etenevät vasemmalta oikealle saapuen lopulta lopulliseen ulostulokerrokseen, joka edustaa tulosta numeerisessa muodossa.
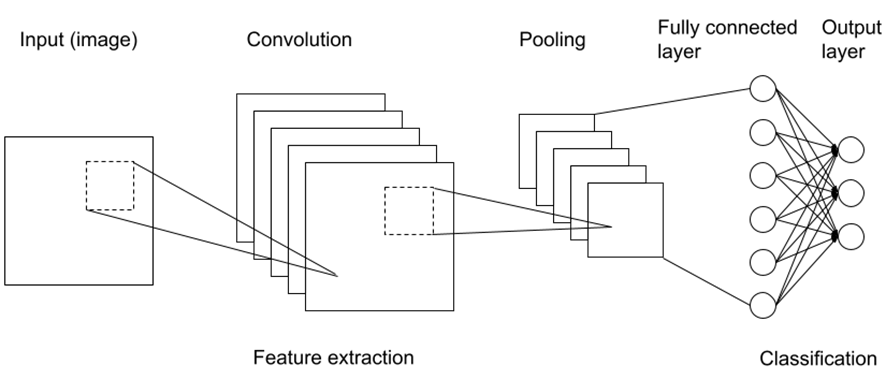
ANN:iin verrattuna kuvien luokittelutulokset paranevat merkittävästi, kun siirrytään läpimurtoteknologiaan, konvoluutineuroverkkoon (Convolutional Neural Network, CNN) (Marmanis 2016). CNN-arkkitehtuuri parantaa ANN-arkkitehtuuria lisäämällä konvoluutio- ja pooling-kerroksia. Uudet kerrokset yksinkertaistavat ja poimivat kuvan piirteitä säilyttäen samalla piirteiden sijainnin alkuperäiseen kuvaan nähden (kuva 2). Pooling-kerrokset skaalaavat alkuperäisen kuvan pienemmäksi ja konvoluutiokerrokset havaitsevat kuvasta enemmän korkeamman asteen piirteitä. CNN-arkkitehtuurin avulla tietokonenäkö kykenee ihmisen tasoiseen tai korkeampaan tarkkuuteen (Galanty 2021).
CNN-arkkitehtuuri luokittelee vain yhden kuvan yhtenä kokonaisuutena. Projektin tavoitteena oli tietokonenäön avulla havaita yhdestä kuvasta useita eri kasvuvaiheessa olevia marjoja. Siksi tarvitaan objektin havaitsemisarkkitehtuuria kuvanluokitteluarkkitehtuurin sijaan, sillä objektin havaitsemisella pyritään myös paikantamaan instanssit niiden luonnollisesta taustasta (Liu 2018).

Projektissa käytettiin objektin havaitsemisarkkitehtuurina YOLO-algoritmia (You Only Look Once). YOLO on suunniteltu nopeaksi, yksinkertaiseksi ja tarkaksi (Redmon 2015). YOLO-prosessi jakaa kuvan ruudukkoon ja havaitsee kohteet kussakin ruudukossa ja tunnistaa kohteiden ulottuvuudet (Bounding Box). Bounding box -tulokset yhdistetään kunkin ruudukon luokittelutodennäköisyyteen tarkempien tulosten suodattamiseksi (Redmon 2015). YOLO-prosessi on visualisoitu kuvassa 3. Hankkeessa käytettiin YOLO:n versiota 5, koska se on rakennettu PyTorch-kehitysalustan avulla (Solawetz 2020), mikä helpotti sen käyttöönottoa. Lisäksi YOLOv5 mahdollistaa datan augmentoimisen koulutusprosessissa (Benjumea 2021).
Datasta prototyypiksi
Syväoppimisen koulutusaineisto muodostettiin ottamalla tuhansia marjakuvia. Noin 10 000 kuvaa kerättiin pääasiassa kuluttajatason matkapuhelimilla. Yksi alkuperäisen projektisuunnitelman ideoista oli päästä lähemmäs marjasadon mittausten joukkoistamista helppokäyttöisen mobiilisovelluksen avulla. Tämän vuoksi koulutus oli tarkoitus tehdä pääosin yleisesti saatavilla olevilla puhelimilla.

Aineiston keräämisen jälkeen ja sen aikana aloitettiin annotointiprosessi. Annotointiprosessi oli hyvin työläs, eikä kaikkia kuvia saatu annotoitua resurssien rajallisuuden vuoksi. Annotaatioprosessi on yksinkertaisuudessaan oikean marjaluokan manuaalinen piirtäminen kuvan päälle. Merkittävä vaikeus oli se, että marjat ovat pieniä ja varsinkin raakamarjat piiloutuvat hyvin taustaa vasten. Kun annotoitujen kuvien pääaineisto oli valmis, aloitettiin lisäannotointiprosessit aineiston tasapainottamiseksi. Tasapainoinen aineisto on koulutusaineisto, jossa on suunnilleen yhtä monta annotointia kustakin luokasta. Lopullinen aineisto muodostui kuudesta luokasta, jotka ovat esitetty esimerkkien avulla kuvassa 4.

Tiheyden kaava on instanssien lukumäärä jaettuna pinta-alalla. Tietokonenäköä käytettiin marjojen lukumäärän arviointiin, mutta koko kuvan pinta-ala-tietoa ei ollut saatavilla laskennan tukena. Tämän vuoksi myös kenttämittauksen laskentakehykset annotoitiin tiheyden arviointia varten kuvan 5 mukaisesti. Kehyksen monikulmiota käytettiin syväoppimisella havaittujen marjojen rajaamiseen, ja näin kaikki kuvaan jääneet marjat olivat sisällä yhden m²:n tai 0,25 m²:n alueelta. Kahta erikokoista laskentakehystä käytettiin, jotta olisi mahdollista verrata korrelaatioeroja lähempänä ja kauempana maasta otetuissa kuvissa.
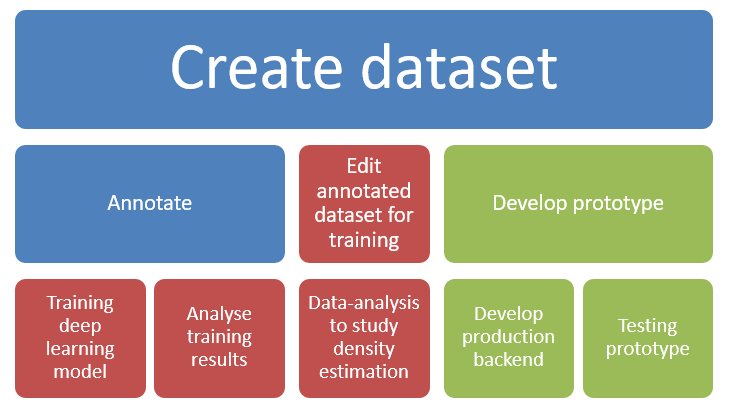
Marjamasiina-hankkeen tehtävät havainnollistettiin kuvassa 6. Merkittävä määrä työtä käytettiin koulutustulosten analysointiin ja iteratiiviseen parantamiseen. Koulutustulosten parantaminen tarkoitti sitä, että lisättiin annotaatiota, koska aineisto ei joskus ollut tarpeeksi tasapainossa. Tietokone ei ollut ainoa, jolla oli vaikeuksia marjojen havaitsemisessa. Myös ihmisille annotointi oli vaikeaa, koska kuvissa oli paljon vaikeasti erottuvia marjoja. On todennäköistä, että jos ihmiset ohjeistettaisiin annotoimaan samoja marjakuvia päällekkäin, tulokset vaihtelisivat.
Tärkein aineiston käsittely ennen koulutusta oli kuvan jakaminen pienempiin osiin. Hankkeessa käytetyn YOLOv5-mallin natiiviresoluutio oli 640×640 pikseliä. Suuremman kuvan suoraan käyttäminen tarkoitti sen kutistamista natiiviresoluutioon. Koska kuvat otettiin esimerkiksi 4032×3024-resoluutiolla, yksityiskohtia hävisi merkittävästi kuvaa pienennettäessä, mikä on haitallista marjojen kaltaisten pienten objektien havaitsemisessa. Tämän vuoksi kaikki annotoidut kuvat, jotka olivat annotoitu alkuperäisessä resoluutiossaan, ja kaikki kuvat, joista etsittiin koneellisesti marjoja, jaettiin pienempiin kuviin ennen tunnistamista sekä koulutusta. Aluksi käytettiin monimutkaista kuvanjakoalgoritmia, jossa oli päällekkäisiä zoomaustasoja, mutta jakoprosessi palautettiin yksinkertaisempaan prosessiin yhdellä zoomaustasolla. Yksinkertaisemman prosessin tuomat selkeyden edut olivat suuremmat kuin monimutkaisemman menetelmien käyttö. Jälleen kerran yksinkertaisuus voittaa.
Koulutusiteraatiot eivät sinänsä olleet liian työläitä, mutta syväoppimista parannettiin muokkaamalla aineistoa ja aineiston esikäsittelyä, mikä oli aikaa vievää. Projektiaikaa kului myös jälkikäsittelyyn, sillä koulutustulokset edellyttivät analyysiä ja koulutetun mallin laadun tarkistamista joissakin tapauksissa vertailuaineiston avulla.
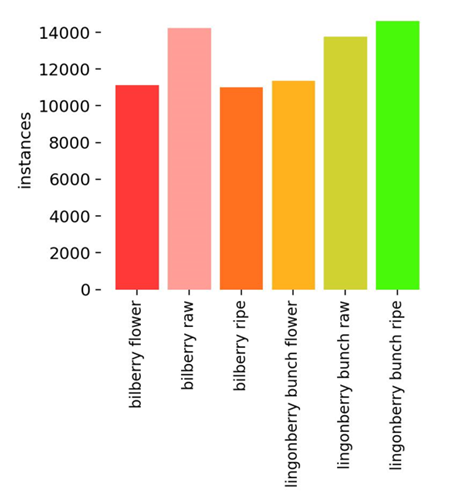
Lopullinen koulutukseen käytetty 640×640 pikseliin normalisoitujen kuvapalojen koulutustietokanta oli 41 101 kuvaa, joissa oli 95 065 annotoitua marjaa. Aineistoa täydennettiin synteettisellä datalla, joka luotiin lisäämällä satunnaisia leikattuja marjakuvia läpinäkyvillä taustoilla erilaisten taustakuvien päälle. Taustakuvat olivat enimmäkseen kampuksen ympäristössä otettuja kuvia ja valkoisia taustakuvia. Kuvassa 7 esitetään lopullisen aineiston tasapaino. Tasapainoa pidettiin kuvaajan perusteella riittävänä.
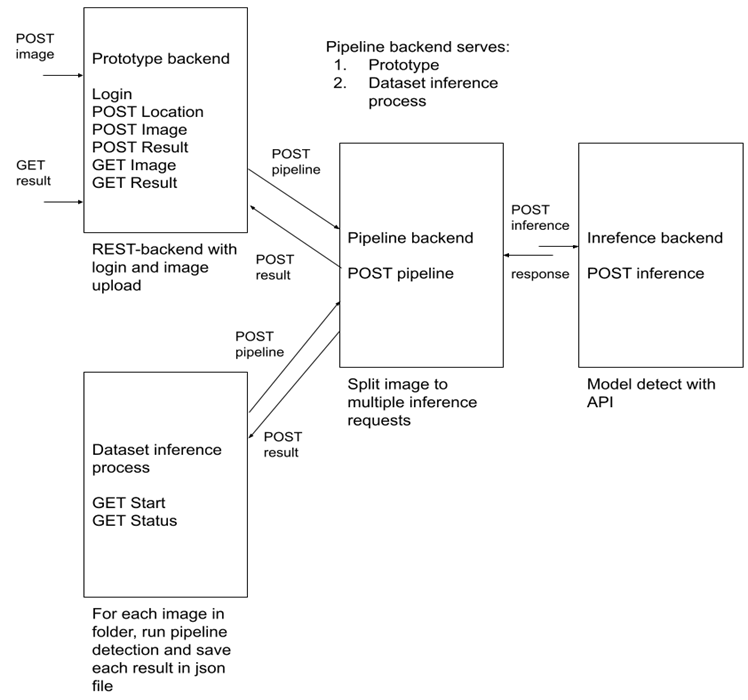
Kuten kuvassa 8 on esitetty, projektin backend-arkkitehtuuri muodostettiin neljästä erillisestä palvelusta. Protoyypin rajapinta (Prototype backend) oli prototyyppimobiilisovelluksen käyttämä rajapinta. Protoyypin rajapinnan päätehtäviä olivat kirjautumisominaisuuden lisääminen, kuvavarastona toimiminen ladattaville kuville sekä sijaintitiedon ja tulosten tallentaminen. Aineiston tunnistusprosessin (Dataset inference process) -palvelun tehtävänä oli suorittaa tunnistamisprosessi eräajona tuhansille kuville ja tallentaa tulokset data-analyysia varten. Tuloksena havaittuja marjoja käytettiin tiheydenarviointitutkimuksessa. kuvanjakorajapinnan (Pipeline backend) päätehtävänä oli jakaa kuva paloihin ja pyytää koneoppimisrajapintaa (inference backend) etsimään marjoja jokaisesta kuvapalasta. Kun kaikki kuvapalat oli suoritettu koneoppimisrajapinnassa, havaittujen marjojen sijainti kuvapalassa muunnettiin alkuperäisen pääkuvan koordinaatistoon. Lopuksi kaikki tulokset lähetettiin alkuperäisessä pyynnössä määriteltyyn osoitteeseen. Viimeinen rajapinta oli aikaisemmin jo osittain kuvattu koneoppimisrajapinta, joka suoritti koneoppimismallin tunnistaen marjat kuvasta.
Prototyyppisovelluksen kehittäminen aloitettiin heti sen jälkeen, kun ensimmäinen käyttökelpoinen malli oli koulutettu. Tärkein arkkitehtuurinen päätös prototyyppisovelluksen taustapalvelun osalta oli rakentaa varsinainen koneoppimisrajapinta erilliseksi palveluksi. Päätös tehtiin, jotta rajapinta voitaisiin tarvittaessa ottaa käyttöön erillisessä grafiikkaprosessoriyksiköllä (Graphical Processing Unit, GPU) varustetulla palvelimella. Kuvanjakorajapinta kehitettiin erilliseksi palveluksi, jotta prototyyppisovelluksen käyttämää rajapinta voitiin säilyttää mahdollisimman yleisrajapintana. Näin prototyypin rajapinta voitiin helpoiten toteuttaa valmiilla headless API-ohjelman avulla. Kuvanjakorajapinnan erillisyys mahdollisti kuvanjakorajapinnan käytön prototyypin rajapinnan ohi kuvassa 8 esitetyllä tavalla. Modulaarinen arkkitehtuuri erottaa huolenaiheet luotettavammin toisistaan, mutta käytännössä huomattiin, että kehitettäessä useiden palvelujen päivitys hidasti kehitysprosessia merkittävästi ja lisäsi ylläpidon monimutkaisuutta.
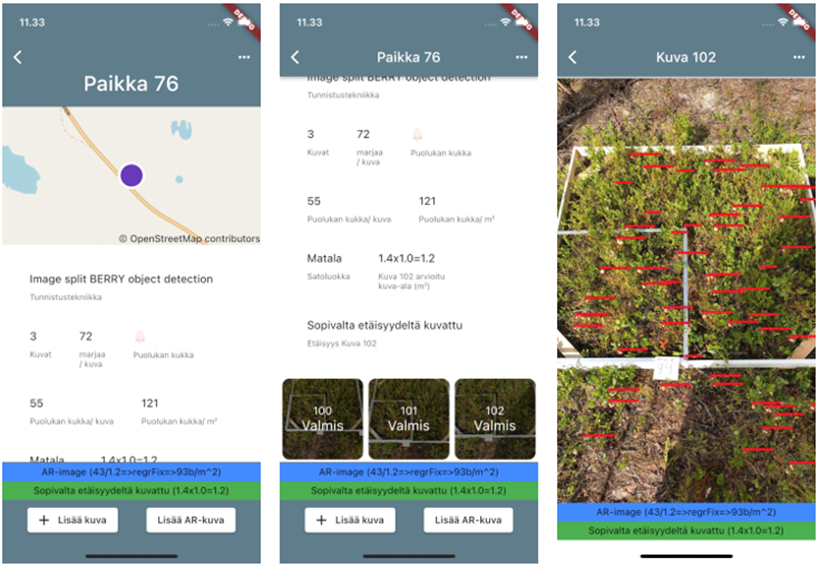
Prototyyppisovellus kehitettiin käyttäen Flutter-monialustakehitysympäristöä, joka mahdollistaa sekä IOS-, web- että Android-kehityksen samalla koodipohjalla (GitHub.com 2022). Ollessaan fyysisellä mittauspaikalla, käyttäjä loi uuden paikan prototyypin käyttöliittymästä. Paikan näkymä on kuvassa 9. Paikkanäkymässä näytettiin muun muassa arvioitu marjatiheys. Kohdemarjojen vaihe ja laji määriteltiin useista kuvista havaitun näkyvimmän marjan perusteella. Tiheys arvioitiin kaikkien kuvien keskiarvona ja korjattiin korrelaatioanalyysistä johdetulla lineaarisella regressiokaavalla. Kuvan pinta-alan arviointia testattiin kahdella eri menetelmällä. Ensimmäinen menetelmä oli pinta-alan arviointi marjojen keskikoon perusteella. Toinen menetelmä oli arvioida pinta-ala käyttämällä lisätyn todellisuuden (AR, Augmented Reality) kirjastoa. AR toteutettiin vain Applen IOS-laitteissa.
Tulokset
Hankkeessa saatiin useita erilaisia tuloksia: Syväoppimisen havaintomallin tulokset ja tiheyden arvioinnin tulokset. Tunnistustuloksia käsitellään ensin. Tulokset ovat viimeisestä koulutusiteraatiosta.
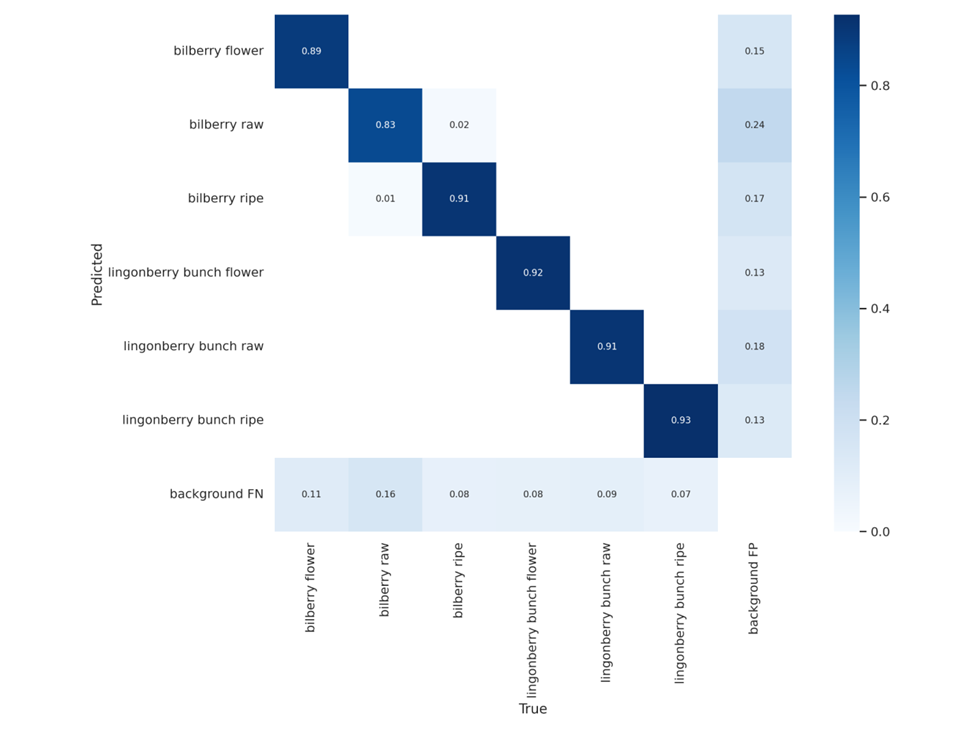
YOLOv5-syväoppimisprosessissa annotoitujen kuvapalojen aineisto jaettiin kolmeen osaan: Koulutus- testi- ja validointiaineisto. Koulutusaineistoa käytettiin mallin kouluttamiseen, testiaineistoa käytettiin mallin edistymisen seuraamiseen koulutuksen aikana ja validointiaineistoa käytettiin lopulliseen testaukseen koulutuksen päätyttyä. Validointiaineiston tulosten mukaan havaitsemisaste oli 83-93 prosenttia luokasta riippuen. Tulokset esitetään kuvassa 10 olevan sekaannusmatriisin avulla. Sekaannusmatriisi kuvaa todellisia arvoja vastaavien ennustettujen havaintojen prosenttiosuuksia. Havaittujen kypsän mustikan kohdalla sekaannusmatriisista on luettavissa, että 1 % oli annotoitu raaoiksi mustikoiksi, 91 % oli oikein ja 17 % havaituista kypsistä mustikoista oli osa taustaa. Sekaannusmatriisin mukaan kypsät puolukat olivat parhaiten tunnistettu luokka, kun taas raaka mustikka oli selkeästi huonoin. Kaiken kaikkiaan tuloksia pidettiin hyväksyttävinä.

Koneoppimismallia käytettiin tiheyden arviointitutkimusta varten etsimään marjoja lähes 5000 kuvasta, joissa oli yhden m²:n ja 0,25 m²:n kehykset. Tämän jälkeen kuvista havaittuja marjoja rajattiin kehysten avulla siten, että vain sisimmät marjat säilytettiin (kuva 11).
arvioitu tiheys = (oikean tyyppisten havaittujen marjojen lukumäärä kehikon sisällä) / (kehikon pinta-ala)
Yhtälö 1. Arvioidun marjatiheyden laskenta.
Tiheyden laskemista varten pinta-ala toimi kuvassa olevan kehyksen pinta-ala ja marjojen lukumäärä oli kuvasta syväoppimisen avulla havaittujen saman luokan marjojen arvo rajattuna kehikolla. Jokaisessa kuvatiedoston kansiopolussa määritettiin kohdemarjalaji, kasvuvaihe ja sijainti. Tätä metatietoa käytettiin suodattamaan vain kohdelajit tiheysarvioon. Tiheysarvionti laskettiin kullekin kuvalle yhtälön 1 avulla.
Arvioitu tiheys ei ollut prototyypissä käytetty lopullinen tulos. Oletuksena oli, että kuvassa ei näy kaikkia maassa olevia marjoja, mutta marjojen havaitseminen kuvassa korreloi kenttämittausten kanssa. Lineaarinen regressiokaava johdettiin korrelaation avulla. Prototyypissä oli jokaiselle kuudelle luokalle erillinen regressiokaava.
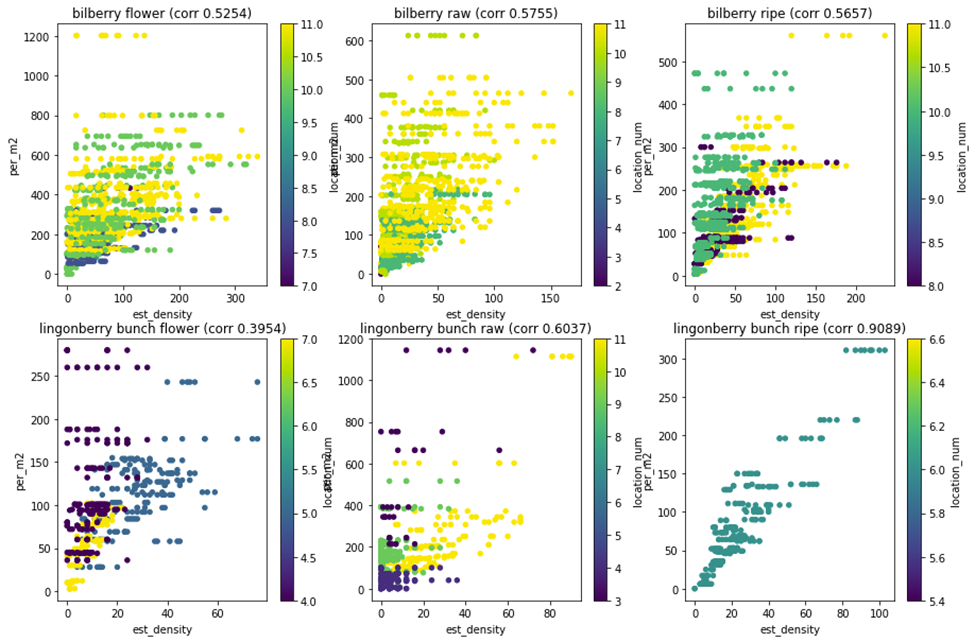
Arvioitu tiheys ja maastolaskennan tulos kuvattuun hajontakuvioon kunkin luokan osalta erikseen (kuva 12). Hajontakuvioiden otsikoissa on kunkin luokan Pearsonin korrelaatio. Hajontakuvio väritettiin sijainnin mukaan, jotta voitiin tutkia, miten sijainti mahdollisesti vaikuttaa havaittujen marjojen ja maastolaskennan väliseen suhteeseen. Hajontadiagrammista on havaittavissa useita asioita:
- Kypsällä puolukalla on vähiten aineistoa ja kaikki kypsät puolukkakuvat ovat vain vuoden 2021 kuvista. Homogeenisempi kypsien puolukoiden aineisto viittaa siihen, että tarvitaan monipuolisempaa aineistoa, sillä homogeeniset aineistot voivat johtaa ennenaikaisiin johtopäätöksiin.
- Jotta korrelaatiota voitaisiin käytännössä käyttää esimerkiksi lineaarisen regression avulla tiheyden arvioimiseksi kuvasta, enemmän muuttujia on otettava huomioon. Sijainnin värittäminen antaa ajatuksia lisäkeinosta parantaa korrelaatiota ottamalla huomioon kasvupaikka.
- Mustikan ja puolukan käyttäytyminen oli erilaista. Mustikan kohdalla mahdollisia kohinan syitä voi olla rehevämpi aluskasvillisuus kuin puolukalla, joka estää marjojen näkymistä kameralle.
- Puolukka havaittiin ryppäänä, mutta kenttämittauksessa puolukat laskettiin yksittäisinä marjoina. Ero marja- ja rypäslaskennan välillä todennäköisesti kasvaa sadon kasvaessa. Puolukka saattaa marjasadon parantuessa kasvattaa enemmän marjoja yksittäisessä ryppäässä.
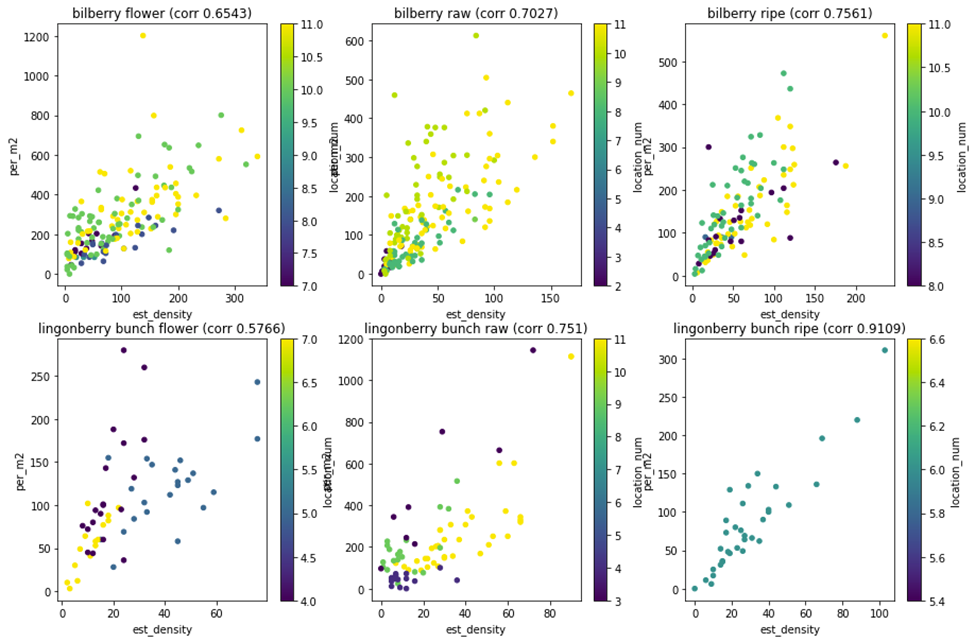
Yksi tapa parantaa korrelaatiotuloksia oli etsiä kaikki samasta kehyksestä otetut kuvat ja käyttää vain sitä kuvaa, jossa on eniten havaittuja marjoja. Teoriassa siis käytetään vain sitä kuvaa, jonka kuvakulma ja laatu on paras koska siinä kuvassa on havaittu eniten marjoja. Tämä tekniikka vaatii useiden kuvien ottamista yhdestä kehyksestä. Käytännön haasteita, miksi kuvissa on eroja kuvanlaadussa, olivat auringon sijainti kameraan (marjat ylivalottuvat tai liian tummia varjoja), kameran tärähtely ja kuvakulma, jossa maakasvillisuus oli enemmän tiellä. Eniten marjoja sisältävän kuvan käyttäminen oli perusteltua, ja maksimiarvokuvasta saatiinkin parempi korrelaatio kuin useiden kuvien keskiarvolla. Maksimiarvokuvan avulla korrelaatio kenttämittausarvon kanssa parani (kuva 13).
Päätelmät
Eri kasvuvaiheissa olevien marjojen havaitseminen kuluttajatason kameroiden ja syväoppimisen avulla tuotti onnistuneita tuloksia. Objektien havaitsemisen koneoppiminen oli erittäin käyttökelpoinen menetelmä vaikeiden tapausten havaitsemiseen luonnollisesta taustasta. Arvokasta tietoa saatiin käytännön koneoppimisprosesseista erityisesti datan esi- ja jälkikäsittelyn osalta. Hankkeessa luotiin suuri ja arvokas koulutusaineisto maastokuvauksilla, annotoinnilla ja synteettisellä aineistolla.

Tiheyden arvioniti ei ollut yksinkertaista kuten monet asiat luonnossa yleensä eivät ole. Hyvä esimerkki haasteista oli kuvassa 14 esitetty mustikka. Korkeatuottoiseen mustikkasatoon liittyy rehevä pohjakasvillisuus. Tämä käänteisesti vähentää havaittujen marjojen määrää kuvassa.
Hankkeessa saatiin syvällisempi näkemys siitä, millä tavoin tiheyttä voidaan arvioida ja miten ongelmaa voidaan lähestyä. Tiheyden arvioinnin suurimmat haasteet olivat marjojen havaitseminen, pinta-alan arviointi ja tiheyden arviointi kerätyn tiedon avulla. Marjojen havaitsemisessa onnistuttiin, mutta tiheyden sekä pinta-alan arvioinnit vaativat lisätutkimuksia.
Pinta-alan arviointia testattiin prototyypissä kahdella eri menetelmällä. Havaittujen marjojen käyttäminen perusmittana kuvan alan arvioinnissa ja käyttöjärjestelmän lisätyn todellisuuden (AR) käytöllä. AR katsottiin pitkällä aikavälillä suositeltavammaksi menetelmäksi. Hankkeen prototyyppi osoitti, että AR:ää voidaan käyttää maapeitteen pinta-alan mittaamiseen, mutta se vaatii huomattavan määrän ohjelmistokehitystä ollakseen riittävän toimintavarma. Haasteita ovat muun muassa tasaisen pinnan havaitseminen käytännössä epätasaisella pinnalla ja jatkuvasti liikkuvan kameran aiheuttaman kohinan käsittely AR-mittauksessa sekä AR:n toteuttaminen yhtä aikaa molemmissa yleisimmissä puhelinten käyttöjärjestelmissä.
Mitä tulee tiheyden arviointiin pinta-alan ja marjojen havaitsemisen tulosten avulla, tarvitaan lisätutkimusta. Korrelaatio on olemassa, mutta se on liian heikko ollakseen käytännöllinen. Käyttäjien ohjaaminen ottamaan useita kuvia ja käyttämään kuvia, joissa on eniten marjoja, on yksi varteenotettava vaihtoehto korrelaation parantamiseksi, mutta enemmän ulottuvuuksia tarvitaan. Marjojen kasvupaikka on lupaava yksi huomioon otettava ulottuvuus.
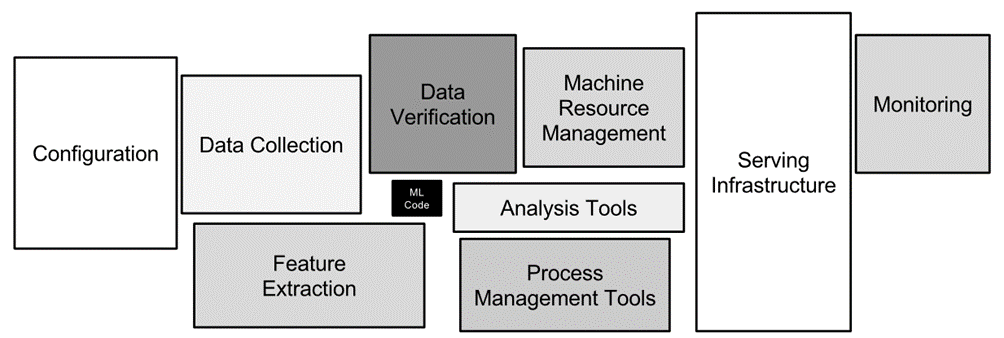
Hankkeen aikana kerättiin huomattava määrä kokemusta syväoppimisprosessista. Saadut käytännön kokemukset ovat yhteneväiset artikkelissa ”Hidden Technical Debt in Machine Learning Systems” esitetyn väitteen kanssa, jonka mukaan koneoppimisjärjestelmillä on erityinen kyky aiheuttaa teknistä velkaa (Sculley 2015). Artikkelissa todetaan myös, että vain pieni osa koneoppimisen järjestelmän koodista on varsinaista kouluttamista tai tunnistamista varten (kuva 15). Marjamasiinaprojektin koodipohja tuki tätä väitettä. Suuri määrä koodia tarvittiin aineiston jälkikäsittelyssä. koneoppimistaustajärjestelmän käyttöönotto modulaarisella rakenteella, versiotarkistusrajapinnat sekä geneeristen ja pyyntö- ja vastausmuotojen käyttö lisäsivät myös koodipohjaa huomattavasti. Viimeinen ja usein unohdettu osa oli analyysiprosessin koodipohja, joiden avulla voitiin tehdä johtopäätöksiä ja ohjata iteratiivista koulutusprosessia oikeaan suuntaan.
Kuten Sculley 2015 totesi, geneeristen pakettien käyttäminen siinä toivossa, että se vähentää tarvittavan ohjelmoinnin määrää, johtaa usein liimakoodiin, jolla geneeriset paketit liitetään yhteen. Liimakoodiongelma johti siihen, että hankkeessa kehitettiin omia kirjastoja hankkeen tarkoituksiin. Versiohallinta oli yksi vaikea näkökohta, sillä koneoppimisjärjestelmää parannettiin muokkaamalla suurta koulutusaineistoa, jota ei hallinnoitu versionhallintajärjestelmällä. Näin ollen on vaikea toistaa tietyn version tuloksia ilman oikeaa, sitä vastaavaa aineistoa.
Koneoppimisjärjestelmän toteuttaminen voi olla haastavaa. Järjestelmään tarvitaan suuri määrä ympäröivää infrastruktuuria. Infrastruktuuri ei ole sinänsä negatiivinen asia, mutta arvokas opetus on ottaa tämä vaatimus huomioon koneoppimisjärjestelmää toteutettaessa. Koneoppimisjärjestelmän toteuttamisen haasteet eroavat tavallisesta ohjelmistoprojektista. Ennen prosessia ja sen aikana kehittäjien on oltava erityisen varovaisia, ettei päädytä täyttämään järjestelmää liimakoodin, kanavaviidakoiden (pipeline) ja abstraktiovelkojen kaltaisilla ”ei-toivotuilla” rakenteilla (anti-pattern) (Sculley 2015).
Kokonaisuudessaan Marjamasiina-projekti oli korvaamaton kokemus täynnä toivoa ja innostusta. Hanke synnytti lukuisia harjoittelupaikkoja ja aloitti kahden kandidaatin ja yhden maisterin opinnäytetyöprosessin. Hankkeessa opittiin koneoppimisjärjestelmän käytännön kehittämisestä. Toivottavasti näemme tulevaisuudessa enemmän koneoppimisen käyttöä, sillä potentiaali on käsin kosketeltava.
Tämä artikkeli perustuu osittain kirjoittajan opinnäytetyöhön ”Berry Density Estimation With Deep Learning: estimating Density of Bilberry and Lingonberry Harvest with Object Detection”, joka on saatavilla osoitteessa https://urn.fi/URN:NBN:fi:amk-2022120927665
Lähteet
Benjumea, Aduen, Izzedin Teeti, Fabio Cuzzolin, and Andrew Bradley. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv preprint arXiv:2112.11798, 2021.
Bohlin, Inka. Maltamo, Matti. Hedenås, Henrik. Lämås, Tomas. Dahlgren, Jonas. Mehtätalo, Lauri. ”Predicting bilberry and cowberry yields using airborne laser scanning and other auxiliary data combined with National Forest Inventory field plot data.” Forest Ecology and Management, Volume 502. ISSN 0378-1127, 2021.
Galanty, Agnieszka . Tomasz Danel, Michał We˛grzyn, Irma Podolak. ”Deep convolutional neural network for preliminary in-field classification of lichen species.” 2021.
GitHub.com. Flutter SDK. 2022. https://github.com/flutter/flutter (retrieved 7. 12 2022).
Gogul, I. and Kumar, Sathiesh. ”Flower species recognition system using convolution neural networks and transfer learning.” 2017.
Kilpeläinen, Harri. Miina, Jari. Store, Ron. Salo, Kauko Salo. Kurttila, Mikko. ”Evaluation of bilberry and cowberry yield models by comparing model predictions with field measurements from North Karelia, Finland.” Forest Ecology and Management, Volume 363. ISSN 0378-1127, 2016. 120-129.
Liu, Li & Ouyang, Wanli. Wang, Xiaogang. Fieguth, Paul. Chen, Jie. Liu, Xinwang. Pietikäinen, Matti. ”Deep Learning for Generic Object Detection: A Survey.” International Journal of Computer Vision. 2018.
marjahavainnot.fi. ”Luonnonmarjojen satohavainnot.” 2022. https://marjahavainnot.fi/assets/info/Havaintometsan_perustaminen_v2.pdf (retrieved 25. 4 2022).
Marmanis, Dimitris and Wegner, Jermaine and Galliani, Silvano and Schindler, Konrad and Datcu, Mihai and Stilla, Uwe. ”SEMANTIC SEGMENTATION OF AERIAL IMAGES WITH AN ENSEMBLE OF CNNS.” ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences. 2016. 473-480.
Redmon, Joseph. Divvala, Santosh Kumar. Girshick, Ross B. Farhadi, Ali. ”You Only Look Once: Unified, Real-Time Object Detection.” CoRR abs/1506.02640. 2015.
Sculley, D. and Holt, Gary and Golovin, Daniel and Davydov, Eugene and Phillips, Todd and Ebner, Dietmar and Chaudhary, Vinay and Young, Michael and Crespo, Jean-François and Dennison, Dan. ”Hidden Technical Debt in Machine Learning Systems.” Advances in Neural Information Processing Systems. 2015.
Solawetz, Jacob. YOLOv5 New Version – Improvements And Evaluation. 29. 6 2020. https://blog.roboflow.com/yolov5-improvements-and-evaluation/ (retrieved 25. 4 2022).
Artikkelijulkaisut ovat FrostBitin asiantuntijakirjoituksia Lapin ammattikorkeakoulun projektien toiminnasta ja tuloksista sekä muita TKI-toimintaa ja ICT-alaa koskevista aiheista. Artikkelit arvioi FrostBitin julkaisutoimikunta.

Mikko Pajula
Mikko on koodaaja ja osa-aikainen opettaja. Hänen ohjelmointitehtävät ovat pääosin full-stack devausta, lisänä asiantuntemus GIS:stä ja syväoppimisesta (deep learning).